文法问题处理器
本文最后更新于:3 年前
# 文法问题处理器
# 问题描述
设计一个文法规则处理器,使其能够实现以下功能:
- 检查并去除有害规则和多余规则
- 消除该文法的左公共因子
- 消除该文法的左递归
- 求出经过前面步骤处理好的文法各非终结符号的 first 集合与 follow 集合
- 对输入的句子进行最左推导分析
- 使用符号’@‘代表’ε’
# 系统流程图
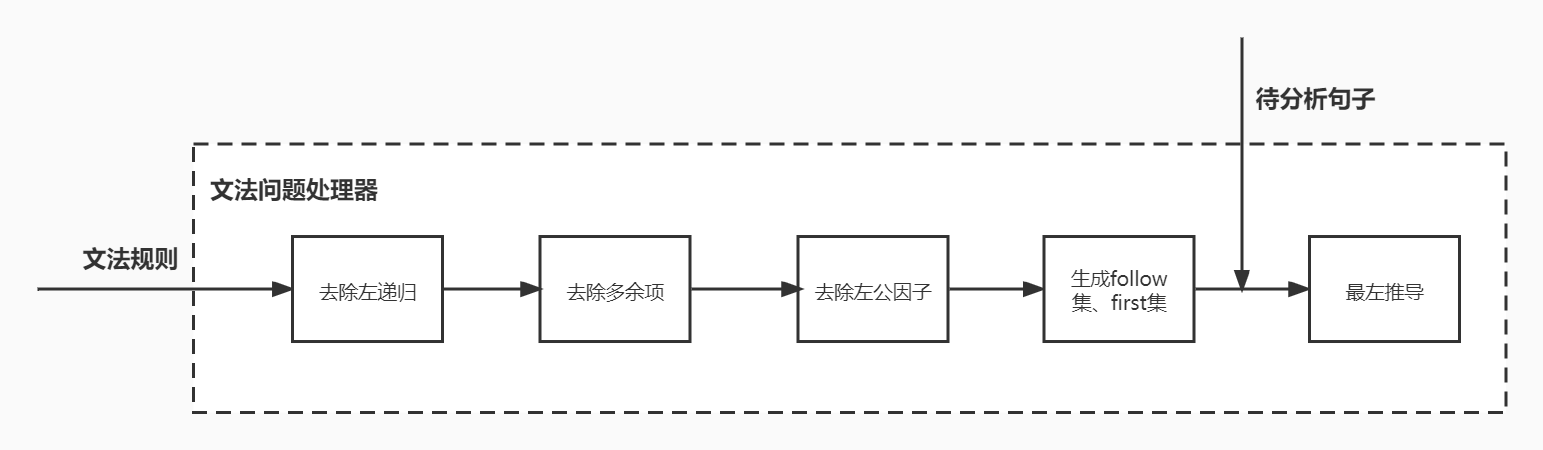
# 存储结构设计
# 文法规则存储结构
对于一条文法规则,使用 string 来存储左边部分,用 vector<vector<string>> 来存储右边部分。
例如:对于文法规则 A -> acd | efg | hig,则右边部分的存储结构为 [[a, c, d], [e, f, g], [h, i, g]]
类声明如下:
1 | |
# 文法处理器存储结构
文法处理器的功能包括对文法的存储以及各种处理操作。
- 使用 vector<LinkNode> 存储多条文法规则
- 使用 vector<string> 存储用户输入的待推导句子、终结符号、非终结符号
- 使用 map<string, set<string>> 存储各个非终结符号对应的 first 集合和 follow 集合
类声明如下:
1 | |
# 界面设计
# 读取文法并做处理的界面
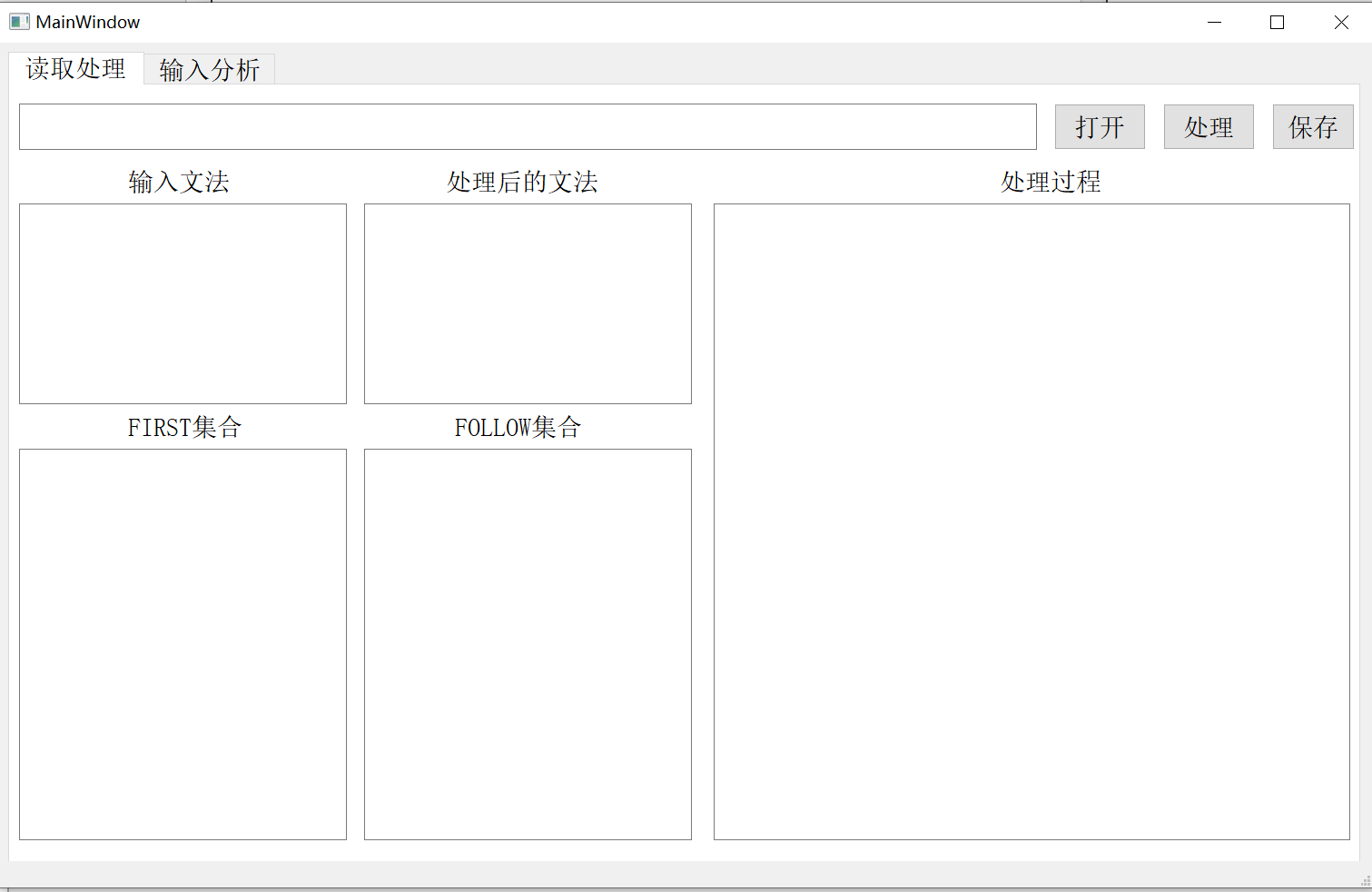
# 最左推导界面

# 主要算法说明
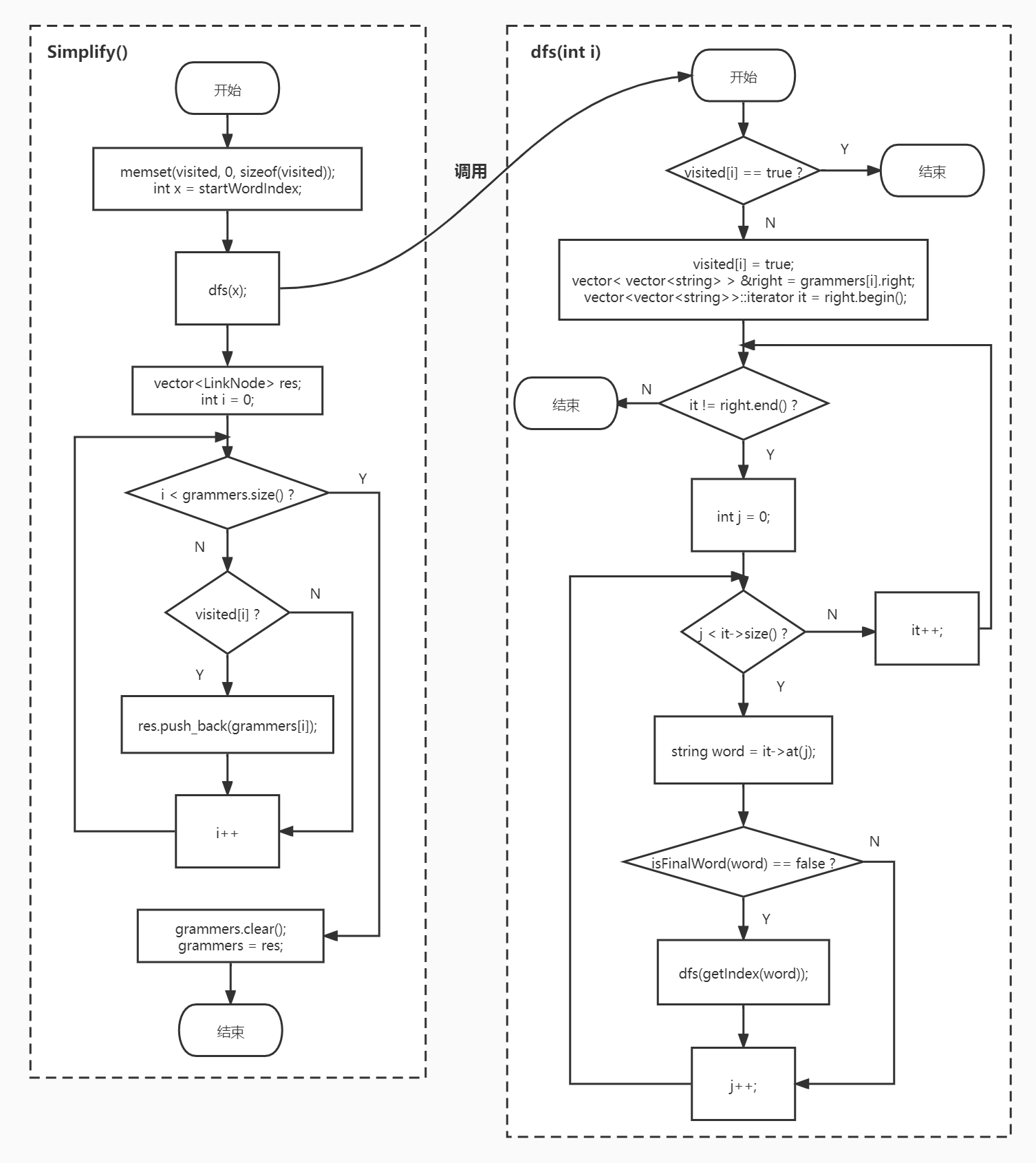
# 去除无效文法
- 对于形如 A -> A 的有害规则,在读取规则时就可以将其去除
- 对于直接或间接无法终止的规则,暂时没想好怎么处理……
- 对于用不到的无效规则,可以采用深度优先的方法,设置一个 bool 数组用于标记是否访问过各条文法规则,从开始结点遍历文法规则,当遍历结束时,对于没有访问过的文法规则,就将其删除
# 去除左递归
- 先将文法右边的非终结符号用其对应的转换规则取代,例如:S -> Qc | c,R -> Sa | a,Q -> Rb | b,就先把 S 带入 R,然后把 R 带入 Q 中,这种做法可以使得间接的左递归也转化成直接左递归
- 然后再开始消除直接左递归,例如 A -> Aa|b,就转换成 A -> bA‘,A’ -> aA’ | ε
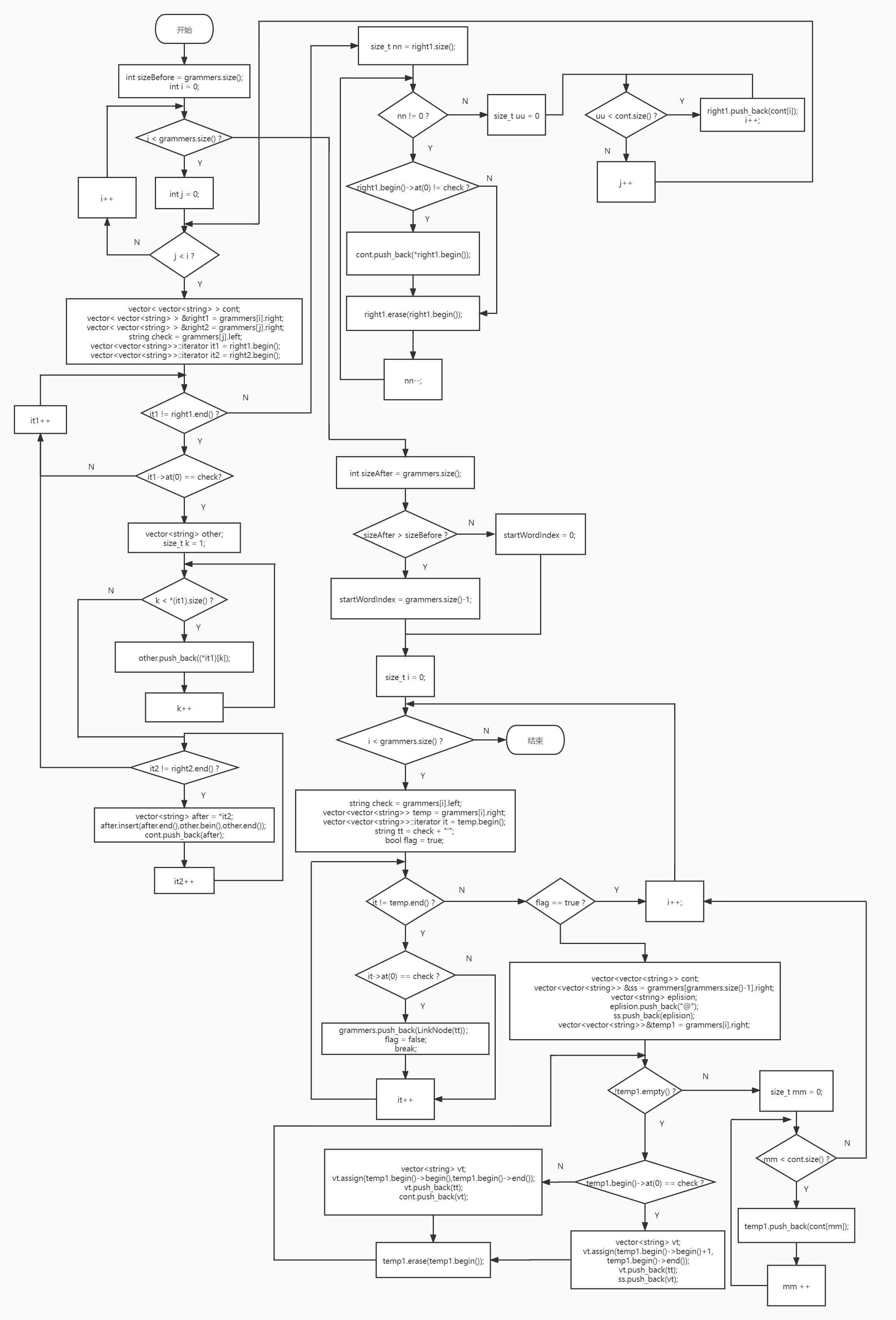
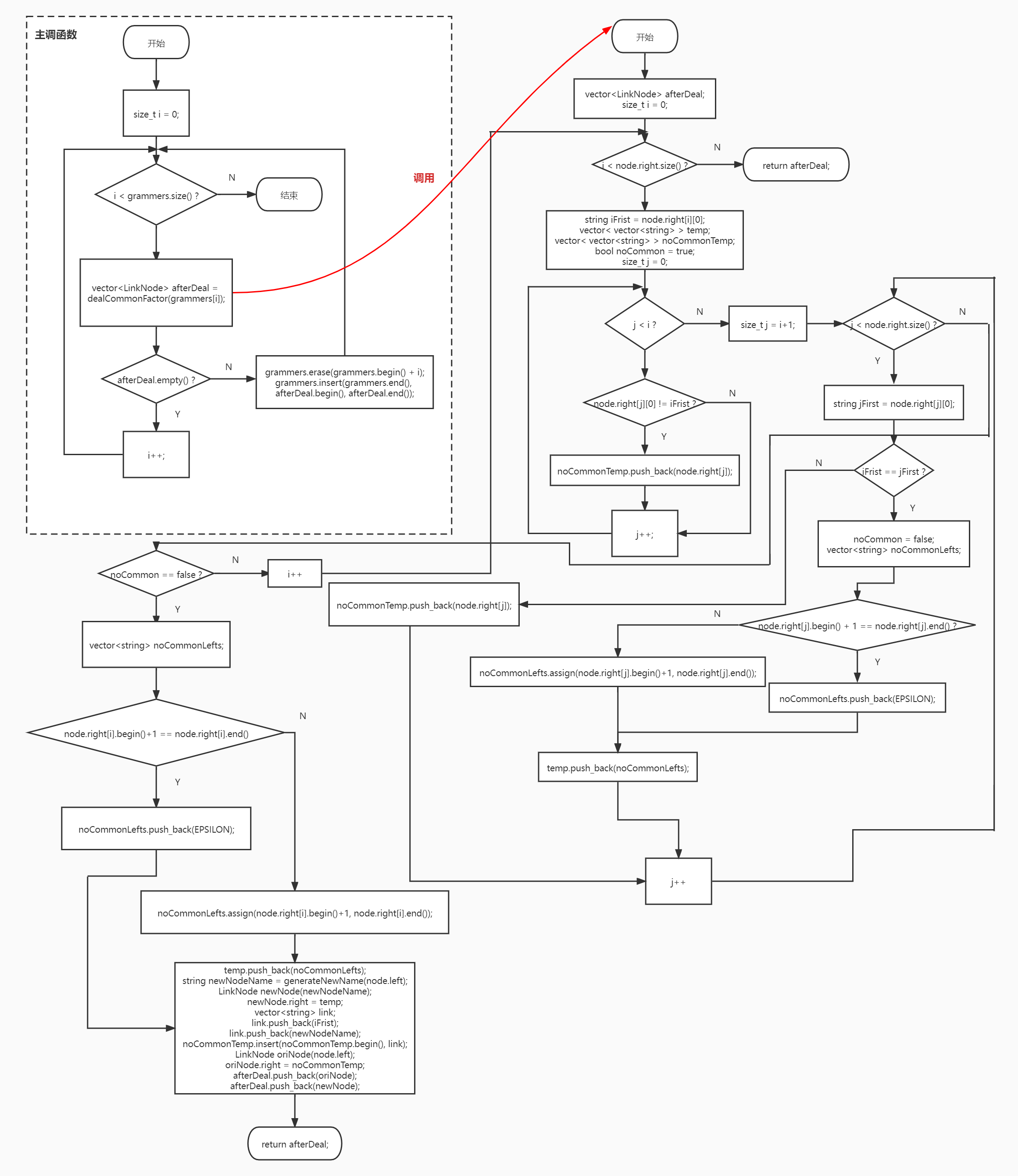
# 去除左公因子
处理的思路是每次只寻找一个左公因子
- 例如 A -> ab | abc
- 第一次处理后变成 A -> aA’,A’ -> b | bc
- 第二次处理后变成 A -> aA’,A‘ -> bA’’,A’‘ -> ε | c
定义从调函数,其功能是对于某条文法规则,若有左公因子,就返回处理好后的(一条变多条)文法规则,若没有左公因子,就返回一个空的 vector;定义一个主调函数,定义变量 i,当 i 小于文法数量时,就一直执行从调函数,若从调函数返回的向量为空,就说明此文法规则无左公因子,那么 i++,否则就将目前处理的文法规则替换为从调函数返回的(多条)文法规则
因为逻辑比较复杂,所以流程图化的有点乱
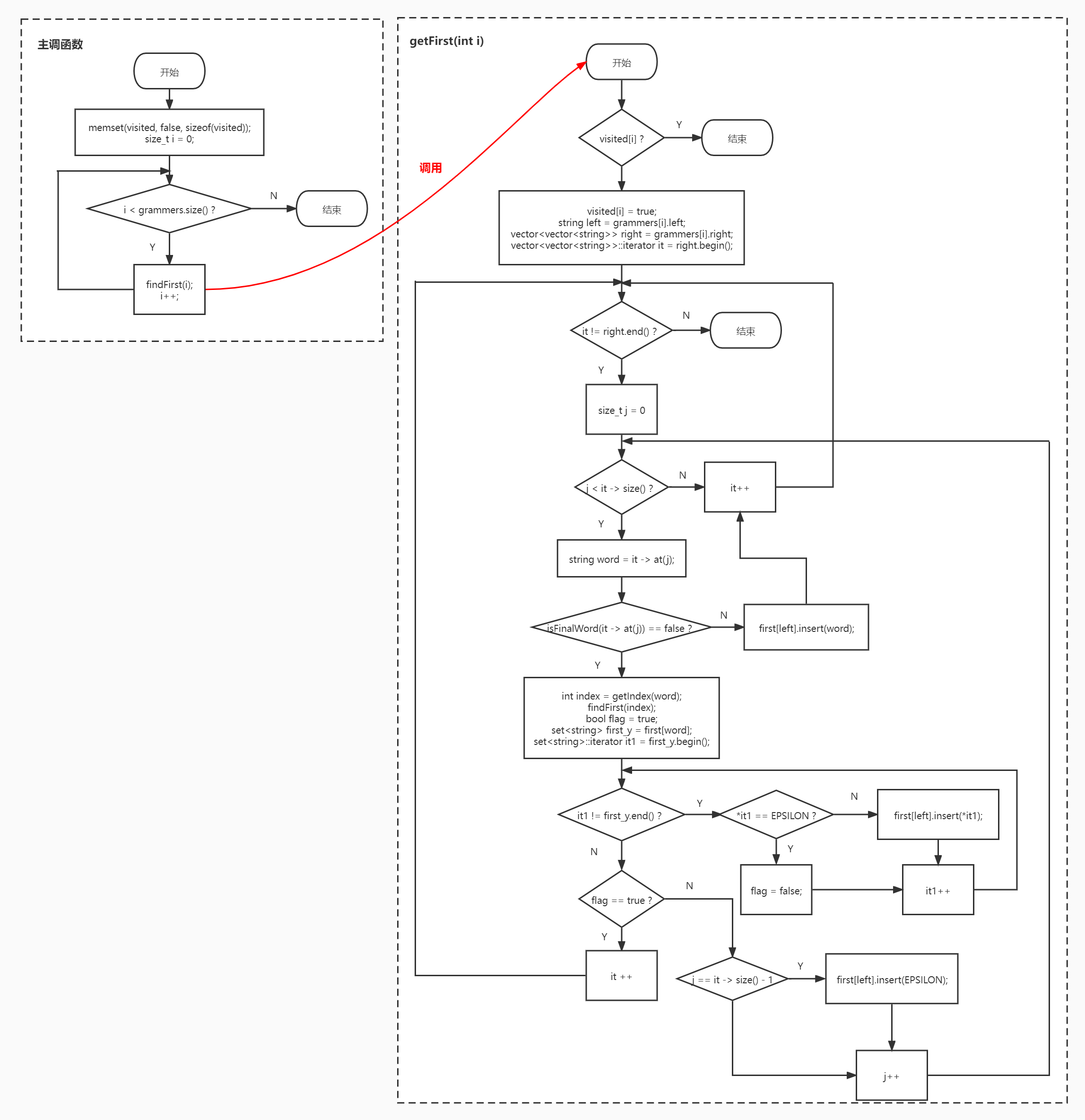
# 求 first 集合
对于规则 X -> x1x2…xn,first (x) 的计算方法如下:
1 | |
# 求 follow 集合
计算 follow 集合的算法如下:
1 | |

# 最左推导
设计一个计数器,表示当前匹配到第几个字符。从开始符号开始执行,每次执行找到当前已生成符号串从左到右第一个非终结符号,查看该终结符号的文法规则:
- 若第一个字符是终结符号,且和待匹配字符相同,就选择该转换
- 若第一个字符是非终结符号,且 first 集合包含待匹配字符,就选择该转换
- 若第一个字符是非终结符号,且 follow 集合包含待匹配字符,就选择 ε 转换

# 其他说明
本文法问题处理器对于以下集中情况暂时无法处理,有待后续改进:
- 直接或间接无法终止的文法规则,目前想到的处理思路是当递归深度超过一定程度时就报错,但是具体实现的时候遇到了问题
- 输入时或处理后出现某条文法规则可以变成’ε’,且 first 和 follow 集合的交集不为空的情况,这个暂时想不到好的办法解决。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!