/* ******************************************** 条件表达式 ******************************************** */ # 查询员工工资大于10000的员工信息 SELECT* FROM employees WHERE salary >10000; /* ******************************************** 逻辑表达式 ******************************************** */ # 查询工资在10000到20000之间的员工信息 SELECT* FROM employees WHERE salary >=10000 AND salary <=20000;
/* ******************************************** 模糊查询 ******************************************** */ /* 模糊查询:LIKE,一般和通配符配合使用。不但可以查字符型,也可以查数值型 '%'代表0或n个字符 '_'代表一个字符 \_代表转义字符'_' */ # 查询员工名中包含'a'的员工信息 SELECT* FROM employees WHERE first_name LIKE'%a%'; # 查询员工名第三个字符为'a',第五个字符为'e'的员工信息 SELECT* FROM employees WHERE first_name like'__a_e%' # 查询员工名第三个字符为'_'的员工信息 SELECT* FROM employees WHERE first_name like'_\_%'; SELECT* FROM employees WHERE first_name like'_$_%'ESCAPE'$'; # 这里表示'$'是转义字符,推荐使用这种 /* BETWEEN a AND b 的区间是闭区间[a,b] b必须>=a,否则筛选出来的结果是0条 */ # 查询工资在10000到20000之间的员工信息 SELECT* FROM employees WHERE salary BETWEEN10000AND20000; /* IN列表的值类型必须一致或兼容 不支持通配符 */ # 查询员工的工种编号是IT_PROG, AD_VP, AD_PRES中的一个的员工信息 SELECT* FROM employees WHERE job_id IN ('IT_PROG', 'AD_VP', 'AD_PRES'); /* '='不能用于判断NULL值,要使用IS NULL或IS NOT NULL */ # 查询没有奖金的员工信息 SELECT* FROM employees WHERE commission_pac ISNULL;# 必须写成isnull,不能写成 =null # 查询有奖金的员工信息 SELECT* FROM employees WHERE commission_pac ISNOT NULL;# 必须写成isnot null,不能写成 !=null # 安全等于'<=>' # ISNULL 可以写成<=>NULL # 查询工资为12000的员工信息 SELECT* FROM employees WHERE salary <=>12000; /* IS NULL只能判断NULL值 <=> 既可以判断NULL值,也可以判断普通的数值,但可读性较低 */ # ISNULL(expr)如果expr是NULL,就返回1,否则返回0 SELECT ISNULL(commission_pac) FROM employees;
# IF():实现if-else的效果 SELECT IF(expr1, expr2, expr3); # 若expr1为真,返回expr2,否则expr3 # CASE函数,使用一:类似于Java中switch case的效果 /* 格式: case 要判断的字段或表达式 when 常量1 then 要显示的值或语句1;(值的时候不加';',语句的时候加';') when 常量2 then 要显示的值或语句2; ... else 要显示的值或语句2; end [as new_name] */ SELECT salary, department_id, CASE department_id WHEN30THEN salary *1.1 WHEN40THEN salary *1.2 ELSE salary *1.2 ENDAS'新工资' FROM employees # CASE函数,使用二:类似于Java中的多重if /* CASE WHEN 条件1 THEN 要显示的值或语句1;(值的时候不加';',语句的时候加';') WHEN 条件2 THEN 要显示的值1或语句2; ... ELSE 要显示的值1或语句2; END */ SELECT salary, CASE WHEN salary >12000THEN'A' WHEN salary >10000THEN'B' ELSE'C' ENDAS rank FROM employees
# 等值连接 # 例:查询女生对应的男生 SELECT'name', boy_name FROM girls, boys WHERE girls.boyfriend_id = boys.id; # 例:查询员工名和对应的部门名 SELECT last_name, department_name FROM employees, departments WHERE employees.department_id = departmens.departmen_id; # 为表起别名,起了别名后,就不能使用原来的表名了 # 查询员工名、工种号、工种名 SELECT last_name, e.job_id /*因为两个表都有job_id字段,所以要指明*/, job_title FROM employees AS e, jobs AS j WHERE e.job_id = j.job_id; # 配合筛选 # 查询有奖金的员工名、部门名 SELECT last_name, department_name FROM employees AS e, dempartments AS d WHERE e.'deparrment_id'= d.'departmen_id' AND e.commission_id ISNOT NULL; # 配合分组 # 查询每个城市的部门个数 SELECTCOUNT(*), city FROM departments, locations WHERE departments.location_id = locations.id GROUPBY city; # 查询有奖金的每个部门的部门名和部门的领导编号和该部门的最低工资 SELECT department_name, manager_id, MIN(salary) FROM departments, employees WHERE departments.manager_id = employees.manager_id AND commissioin_id ISNOT NULL GROUPBY department_name; # 配合排序 # 查询每个工种的工种名和员工个数,按员工个数降序 SELECT job_title, COUNT(*) FROM employees, jobs WHERE emoloyees.job_id = jobs.job_id GROUPBY job_title DESC; # 多表连接 # 例:查询员工名,部门名和所在城市,按员工名降序排序 SELECT last_name, department_name, city FROM employees e, departments d, locations l WHERE e.department_id = d.department_id AND d.location_id = l.location_id ORDERBY last_name DESC;
# 非等值连接 # 例:查询员工的工资和工资等级 SELECT salary, grade_level FROM employees, job_grades WHERE employees.salary BETWEEN job_grades.lowest_salary AND job_grades.highest_salary;
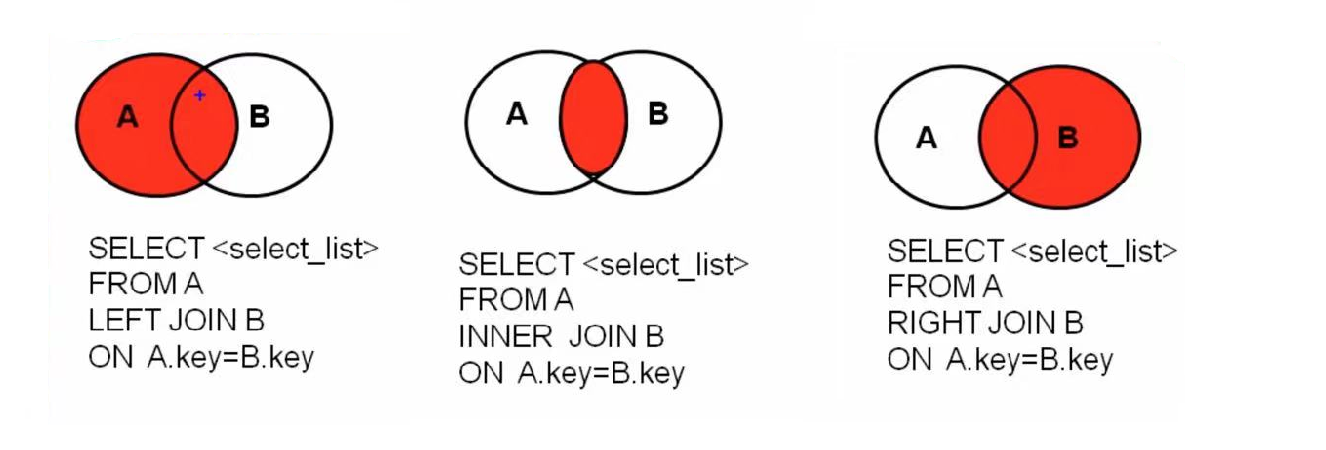
-- 内连接 -- # 等值连接 # 例:查询员工名、部门名 SELECT last_name, department_name FROM employees AS e INNERJOIN departmens AS d ON e.department_id = d.department_id; # 非等值连接 # 例:查询员工的工资级别,按工资从小到大排序 SELECT salary,grade_level FROM employees AS e INNERJOIN job_grades AS g ON e.salary BETWEEN g.lowest_sal AND g.highest_sal ORDERBY salary ASC; # 自连接 # 例:查询员工名和他领导的名字 SELECT e.last_name, m.last_name FROM employees e INNERJOIN employees m ON e.manager_id = m.employee_id;
# 放在WHERE或HAVING后面 # 例1:谁的工资比Abel高 SELECT* FROM employees WHERE salary > ( SELECT salary FROM employees WHERE last_name = "Abel" ); # 例2:查询job_id与141号员工相同,salary比143号员工多的员工信息 SELECT* FROM employees WHERE job_id = ( SELECT job_id FROM employees WHERE employee_id =141 ) AND salary > ( SELECT salary FROM employees WHERE employee_id =143 ); # 例3:查询工资最少的员工的员工信息 SELECT* FROM employees WHERE salary = ( SELECTMIN(salary) FROM employees ); # 例4:查询最低工资大于50号部门的最低工资的部门信息 SELECT department_id, MIN(salary) FROM employees GROUPBY department_id HAVINGMIN(salary) > ( SELECTMIN(salary) FROM employees WHERE department_id =50 ); # 非法使用标量子查询 SELECT department_id, MIN(salary) FROM employees GROUPBY department_id HAVINGMIN(salary) > ( # 这里的结果是一个数salary > 一个列。 应该改成 salary >all (..) SELECT salary FROM employees WHERE department_id =50 ); # 例5:返回location_id是1400或1700的部门中所有员工姓名 SELECT last_name FROM employees WHERE department_id in ( # 或 =ANY(...) SELECT department_id FROM departments WHERE location_id in (1400, 1700) ); # 例6:返回其他工种中比job_id为'IT_PROG'工种任意工资低的员工的信息 SELECT* FROM employees WHERE salary <all( SELECTDISTINCT salary FROM employees WHERE job_id = "IT_PROG" ) AND job_id <> "IT_PROG"; # 例7:查询员工编号最小并且工资最高的员工信息 SELECT* FROM employees WHERE (employee_id, salary) = ( ####### 这种写法不常用 SELECTMIN(employee_id), MAX(salary) FROM employees );
# 例1:查询每个部门的员工个数 SELECT departments.*, ( SELECTCOUNT(*) FROM employees WHERE employee_id = departments.department_id = employees.department_id ) FROM departments; # 例2:查询员工号为102的部门名 SELECT department_name FROM departments AS d INNERJOIN employees AS e ON d.department_id = e.department_id WHERE e.employee_id =102;
# 例1:查询每个部门的平均工资的工资等级 SELECT avg_dep.ag, avg_dep.department_id, g.grade_level FROM ( SELECTAVG(salary) AS ag, department_id FROM employees GROUPBY department_id ) AS avg_dep INNERJOIN job_grades AS g ON avg_dep.ag BETWEEN g.lowest_sal AND g.highest_sal;
# SELECTEXISTS(完整的查询语句):若括号中查询语句不为空,则返回1,否则返回0 # 例1:查询有员工的部门名 SELECT department_name FROM departments WHEREEXISTS( SELECT* FROM employees WHERE employees.department_id = departments.department_id ); # 可以用IN代替 SELECT department_name FROM departments WHERE department_id IN( SELECTDISTINCT department_id FROM employees ); # 例2:查询没有女朋友的男生信息 # 可以用IN实现 SELECT b.* FROM boys WHERE b.id NOTIN( SELECTDISTINCT boyfriend_id FROM girls ); # 也可以用EXISTS代替IN SELECT b.* FROM boys WHERENOTEXISTS( SELECTDISTINCT boyfriend_id FROM girls WHERE b.id = girls.boyfriend_id );
语法:UPDATE 表名 SET 字段名 1 = 新值 1,字段名 2 = 新值 2,…… WHERE 筛选条件
1 2 3 4 5 6 7 8 9
# 例1:修改girls表中姓唐的女生的电话为13899999999 UPDATE girls SET phone ='13899999999' WHERE name LIKE'唐%'; # 例2:修改boys表中id为2的人名称为张飞,魅力值10 UPDATE boys SET boy_name ='张飞', usercp =10 WHERE id =2;
sql92:UPDATE 表 1 别名,表 2 别名 SET 列 = 值,… WHERE 连接条件 AND 筛选条件;
sql99:UPDATE 表 1 别名 连接类型 表 2 别名 ON 连接条件 SET 列 = 值,… WHERE 连接条件 AND 筛选条件;
1 2 3 4 5 6 7 8 9 10 11 12
# 例1:修改张无忌的女朋友们的手机号为114 UPDATE boys b INNERJOIN girls g ON b.id = g.boyfriend_id SET g.phone ='114' WHERE b.name ='张无忌'; # 例2:修改没有男朋友的女生的男朋友编号为2 UPDATE girls g LEFTINNERJOIN boys b ON g.boyfriend_id = b.id SET g.boyfriend_id =2 WHERE g.boyfriend_id ISNULL;
# 删除张无忌的女朋友的信息 DELETE girls # 这里只会删除girls表中的数据 # DELETE girls, boys # 这样就会删除girls和boys两个表中的信息 FROM girls INNERJOIN boys ON boys.id = girls.boyfriend_id WHERE boys.name ='张无忌'
# 删除黄晓明的信息和他女朋友的信息 DELETE girls, boys # 两个表中的信息都会被删除 FROM boys INNERJOIN girls ON boys.id = girls.boyfriend_id WHERE boys.name ='黄晓明'
# 在创建表时设置标识列 CREATE TABLE tab_identity( id INTPRIMARY KEY AUTO_INCREMENT, name VARCHAR(20) )
# 这样,在插入时,就不需要插入id这个字段 INSERT INTO tab_identity VALUES(NULL, 'john'); # 或 INSERT INTO tab_identity(name) VALUES('john'); # 实际上还是可以自己插入id这个值的 INSERT INTO tab_identity VALUES(10, 'john'); # 这样会插入一条数据(10, 'john')
-- 也可以在修改表的时候设置标识列 ALTER TABLE tab_identity ALTERCOLUMN id INTPRIMARY KEY AUTO_INCREMENT; # 删除标识列 ALTER TABLE tab_identity ALTERCOLUMN id INTPRIMARY KEY;
# savepoint的使用 SET AUTOCOMMIT =0; START TRANSACTION; DELETEFROM account WHERE id =25; SAVEPOINT a; # 设置保存点A DELETEFROM account WHERE id =19; ROLLBACKTO a; # 回滚到存档点a
# 创建视图,查询员工中包含字符a的员工名、部门名和工种信息 CREATEVIEW my_view AS SELECT e.last_name, department_name, e.job_id FROM employee e INNERJOIN departments d ON e.departmen_id = d.department_id INNERJOIN jobs j ON e.job_id = j.job_id WHERE e.last_name LIKE'%a%'
修改视图:
CREATE OR REPLACE VIEW 视图名 AS 查询语句
ALTER VIEW 视图名 AS 查询语句
删除视图:DROP VIEW 视图名,视图名,……
查看视图信息:DESC 视图名 或 SHOW CREATE VIEW 视图名
具备以下特点的视图不允许更新:
包含以下关键字的 SQL 语句:分组函数、DISTINCT、GROUP BY、HAVING、UNION、UNION ALL
# 带in模式参数的存储过程 -- 根据女生名,查询对应的男生信息 DELIMITER $ CREATEPROCEDURE test2(IN name VARCHAR(20)) BEGIN SELECT boys.* FROM boys RIGHTJOIN girls ON boys.id = girls.boyfriend_id WHERE girls.name = name END $ -- 调用 DELIMITER ; CALL test2('my_girl_name');
-- 案例2:创建存储过程实现用户是否登录成功 DELIMITER $ CREATEPROCEDURE test3(IN username VARCHAR(20), IN `password` VARCHAR(20)) BEGIN DECLAREresultINTDEFAULT0; # 声明并初始化
SELECTCOUNT(*) INTOresult # 将查询结果赋值给result FROM admin WHERE admin.username = username AND admin.password = `password`;
-- 根据女生名,返回对应的男生名 DELIMITER $ CREATEPROCEDURE test3(IN girl_name VARCHAR(20), OUT boy_name VARCHAR(20)) BEGIN SELECT boys.boy_name INTO boy_name FROM boys INNERJOIN girls ON boys.id = girls.boyfriend_id WHERE girls.name = girl_name; END $ -- 调用 DELIMITER ; SET@boy_name; CALL test3('girl_name', @boy_name);
-- 根据女生名,查询男生名和其对应的魅力值 DELIMITER $ CREATEPROCEDURE test4(IN girl_name VARCHAR(20), OUT boy_name VARCHAR(20), OUT user_cp INT) BEGIN SELECT boys.boy_name, boys.user_cp INTO boy_name, user_cp FROM boys INNERJOIN girls ON boys.id = girls.boyfriend_id WHERE girls.name = girl_name; END $ -- 调用 DELIMITER ; SET@boy_name; SET@user_cp; CALL test4('girl_name', @boy_name, @user_cp);
# 传入a和b两个值,最终a和b翻倍并返回 DELIMITER $ CREATEPROCEDURE test5(INOUT a INT, INOUT b INT) BEGIN SET a = a *2; SET b = b *2; END $ -- 调用 DELIMITER ; SET@m :=1; SET@n :=2; CALL test5(@m, @n);
# CASE函数,使用一:类似于Java中switch case的效果 /* 格式: case 要判断的字段或表达式 when 常量1 then 要显示的值或语句1;(值的时候不加';',语句的时候加';') when 常量2 then 要显示的值或语句2; ... else 要显示的值或语句2; end [as new_name] */ SELECT salary, department_id, CASE department_id WHEN30THEN salary *1.1 WHEN40THEN salary *1.2 ELSE salary *1.2 ENDAS'新工资' FROM employees # CASE函数,使用二:类似于Java中的多重if /* CASE WHEN 条件1 THEN 要显示的值或语句1;(值的时候不加';',语句的时候加';') WHEN 条件2 THEN 要显示的值1或语句2; ... ELSE 要显示的值1或语句2; END */ SELECT salary, CASE WHEN salary >12000THEN'A' WHEN salary >10000THEN'B' ELSE'C' ENDAS rank FROM employees
## 以上是作为表达式的,也可以作为语句单独出现 /* CASE [表达式] WHEN 条件1 THEN 要显示的值或语句1;(值的时候不加';',语句的时候加';') WHEN 条件2 THEN 要显示的值1或语句2; ... ELSE 要显示的值1或语句2; END CASE; */ # 案例:创建存储过程,根据传入的成绩,显示等级 -- 创建 DELIMITER $ CREATEPROCEDURE test(IN grade INT) BEGIN CASE WHEN grade >=90THENSELECT'A'AS'等级'; WHEN grade >=80THENSELECT'B'AS'等级'; WHEN grade >=60THENSELECT'C'AS'等级'; ELSESELECT'D'AS'等级'; ENDCASE; # 作为独立语句的时候,必须写成ENDCASE END $ -- 执行 DELIMITER ; CALL test(90);
特点:
可以作为表达式,嵌套在其他语句中使用,可以放在任何地方,BEGIN END 中或 BEGIN END 的外面
可以作为独立的语句去使用,但只能放在 BEGIN END 中
如果 WHEN 中的条件成立,则执行对应的 THEN 后面的语句,并且结束 CASE,之后的语句不会执行。如果都不满足,则执行 ELSE 中的语句
# 批量插入 DELIMITER $ CREATEPROCEDURE test(IN times INT) BEGIN DECLARE i INTDEFAULT1; WHILE i <= times DO INSERT INTO admin(`user_name`, `password`) VALUES(CONCAT('rose', i), '666'); SET i = i +1; END WHILE; END $
# 批量插入,如果次数超过30,就退出 DELIMITER $ CREATEPROCEDURE test1(IN times INT) BEGIN DECLARE i INTDEFAULT1; tag1: WHILE i <= times DO SET i = i +1; IF I >30THEN LEAVE tag1; END IF; # 配合标签跳出循环 INSERT INTO admin(`user_name`, `password`) VALUES(CONCAT('JACK', i), '777'); END WHILE tag1; END $
# 已知表stringcontent,其中字段:id 自增长,content varchar(20) # 向该表插入指定个数的,随机的字符串 -- 定义存储结构 DELIMITER $ CREATEPROCEDURE test(IN num INT) BEGIN DECLARE i INTDEFAULT1; DECLARE str VARCHAR(26) DEFAULT'abcdefghijklmnopqrstuvwxyz'; DECLARE startIndex INTDEFAULT1; WHILE i <= num DO # 产生一个随机整数,代表起始索引,范围是1-26 SET startIndex =FLOOR(RAND() *26+1;) INSERT INTO stringcontent(content) VALUES(SUBSTR(str, startIndex));# 这样其实没用做到随机,举个例子,将就下 SET i = i +1; END WHILE; END $ -- 调用