# XLEX 软件文档
# 关于
SCNU-CS 编译原理实验二,本来想好好写一写的,但是时间紧迫,先水一水吧,以后有时间再改一改。(还有 bug 没改)
# 作者
@dzcgood
# 开发环境
Qt Creator 4.11.1(Community)
# 顶层程序流程图
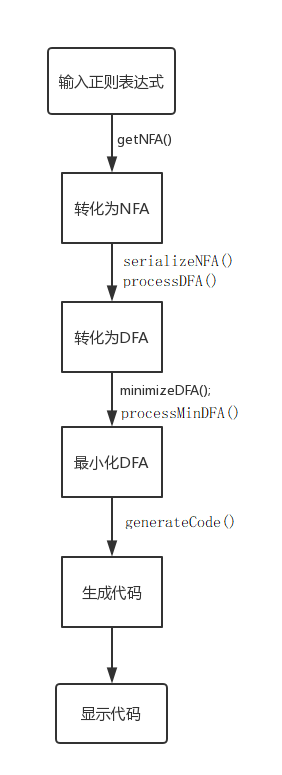
# 实现思路
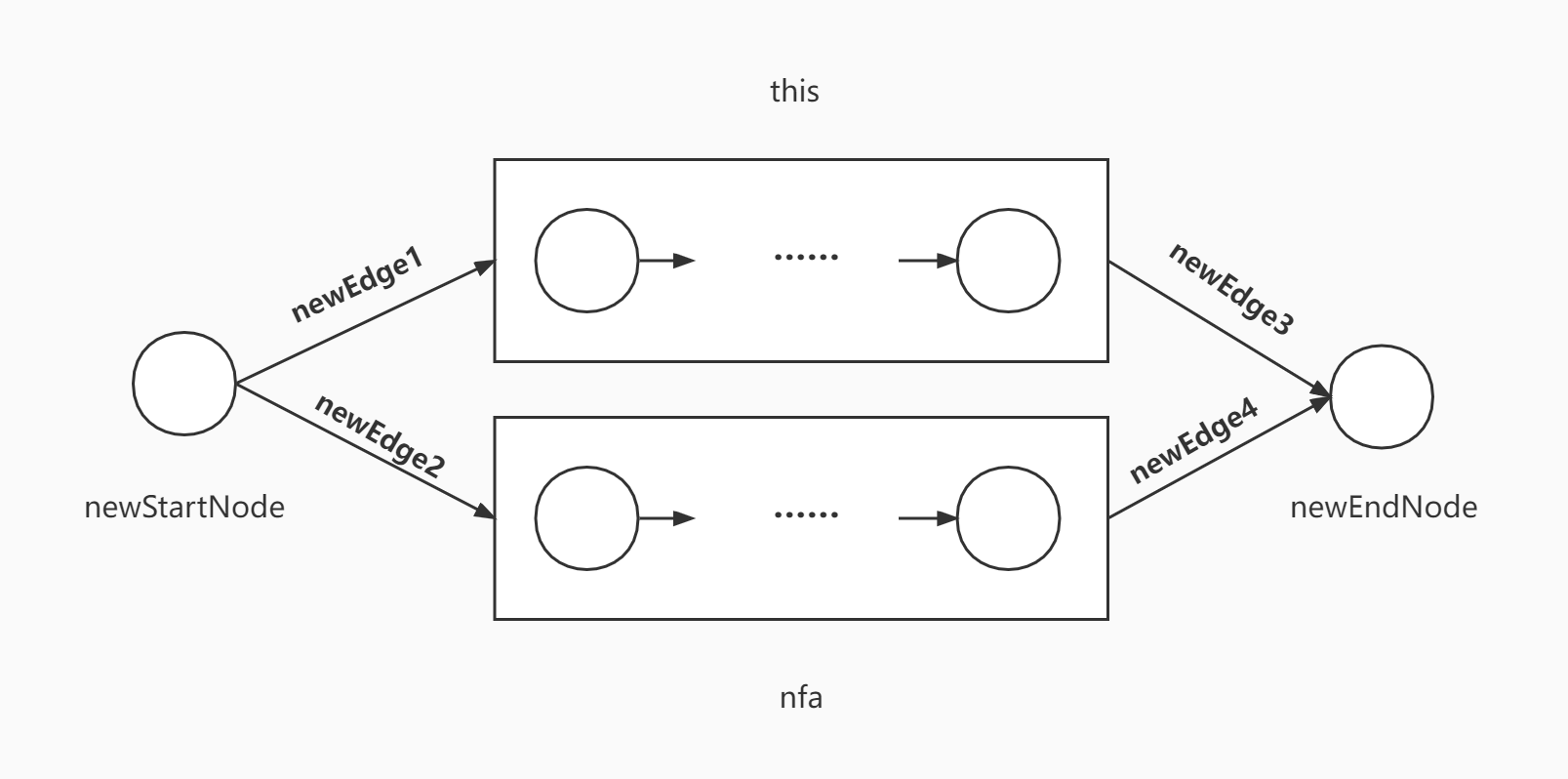
# this | nfa 选择
设 this 和 nfa 都代表一个 nfa 图,则执行‘|’操作只需要新建 startNode 和 endNode 和四条边,将二者连接即可。
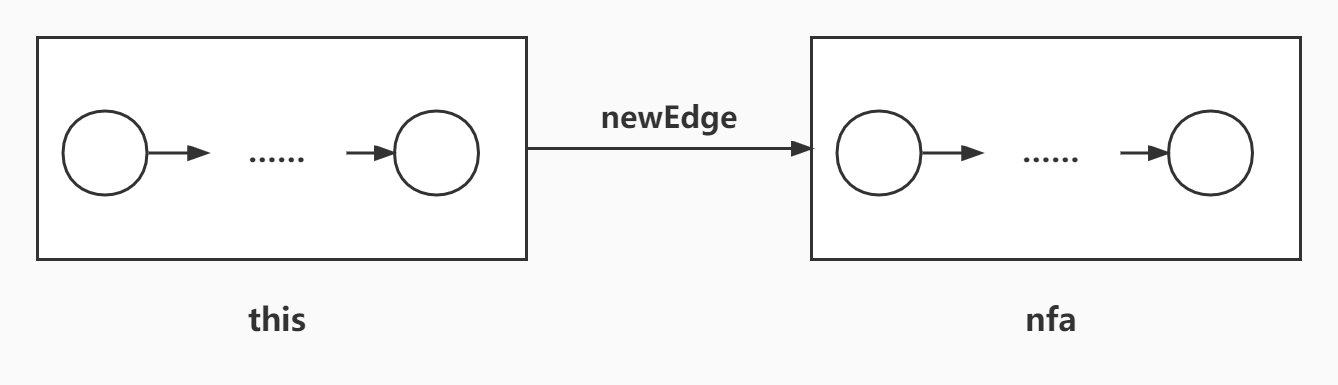
# thisnfa 连接
直接把 this->endNode 和 nfa -> startNode 之间加一条 NFAEdge 连起来
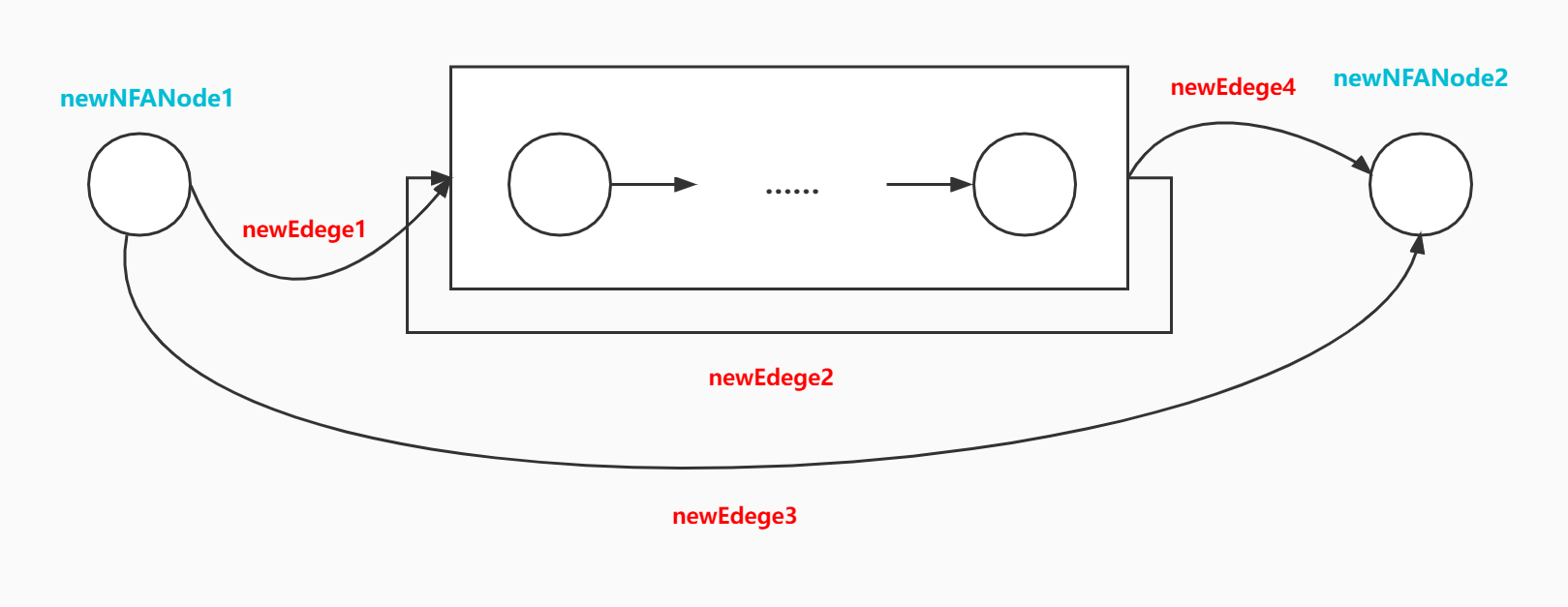
# a* 闭包
需要新建 startNode 和 endNode,和 nfa 前后连起来,然后把 nfa 的 startNode 和 endNode 连起来。总结一下,就是新建两个结点和四条边。
# 生成 NFA
获取 NFA 图,由输入的正则表达式产生 NFA
正则表达式转 NFA 递归方法思路: 首先把 (…) 看成一个单元素 NFA, 和 a 等价,把单个 NFA 看成一个或数个元素的 Union,即 NFA = a [|b|c…]。扫描正则表达式,首先扫描 | 进行拆分递归,逐项建立 NFA 后,用 ‘|’ 连接,对于括号要进行进行递归处理
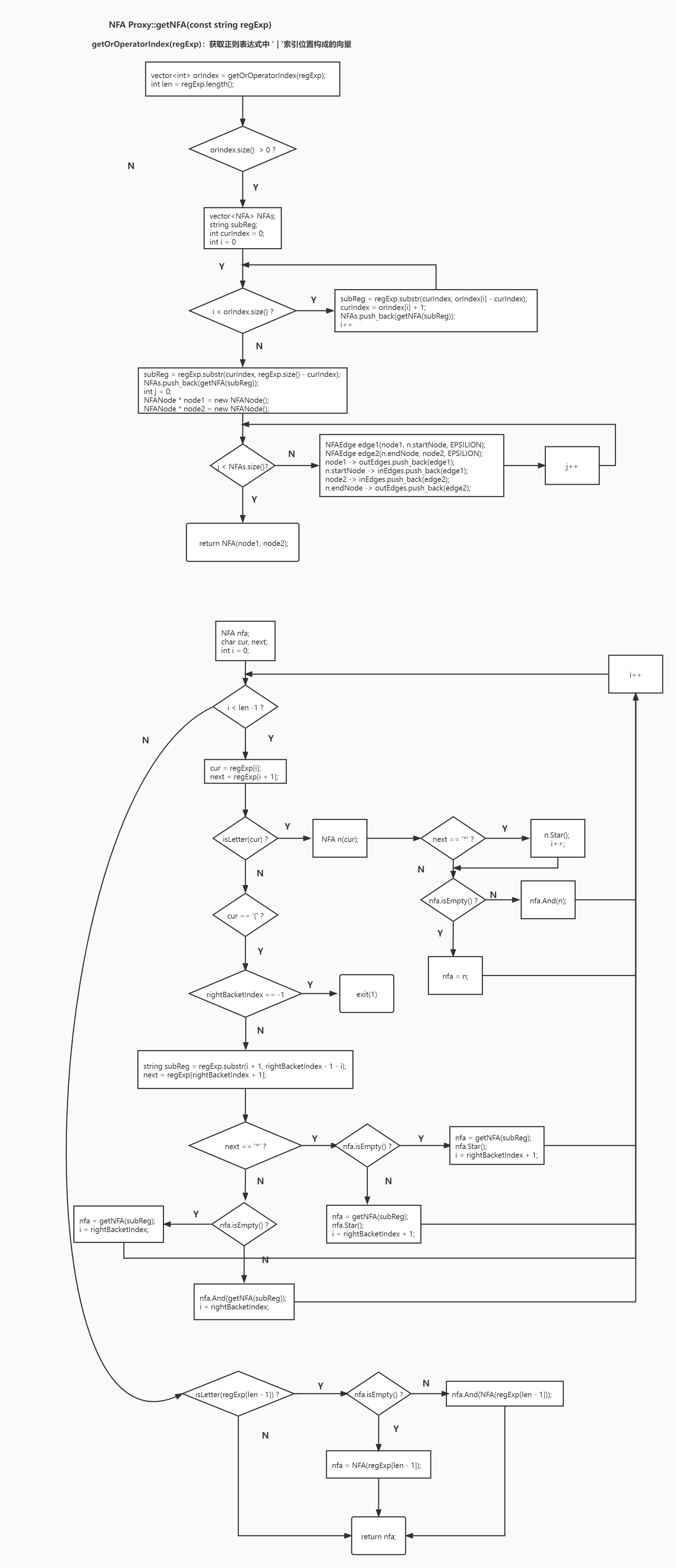
# 生成 DFA
分为两个步骤:
- 给 NFA 的结点编号并建立初始 DFA 结点
- 确定结点与结点之间的关系,建立 DFA 的边
# NFA 结点编号,建立 DFA 结点
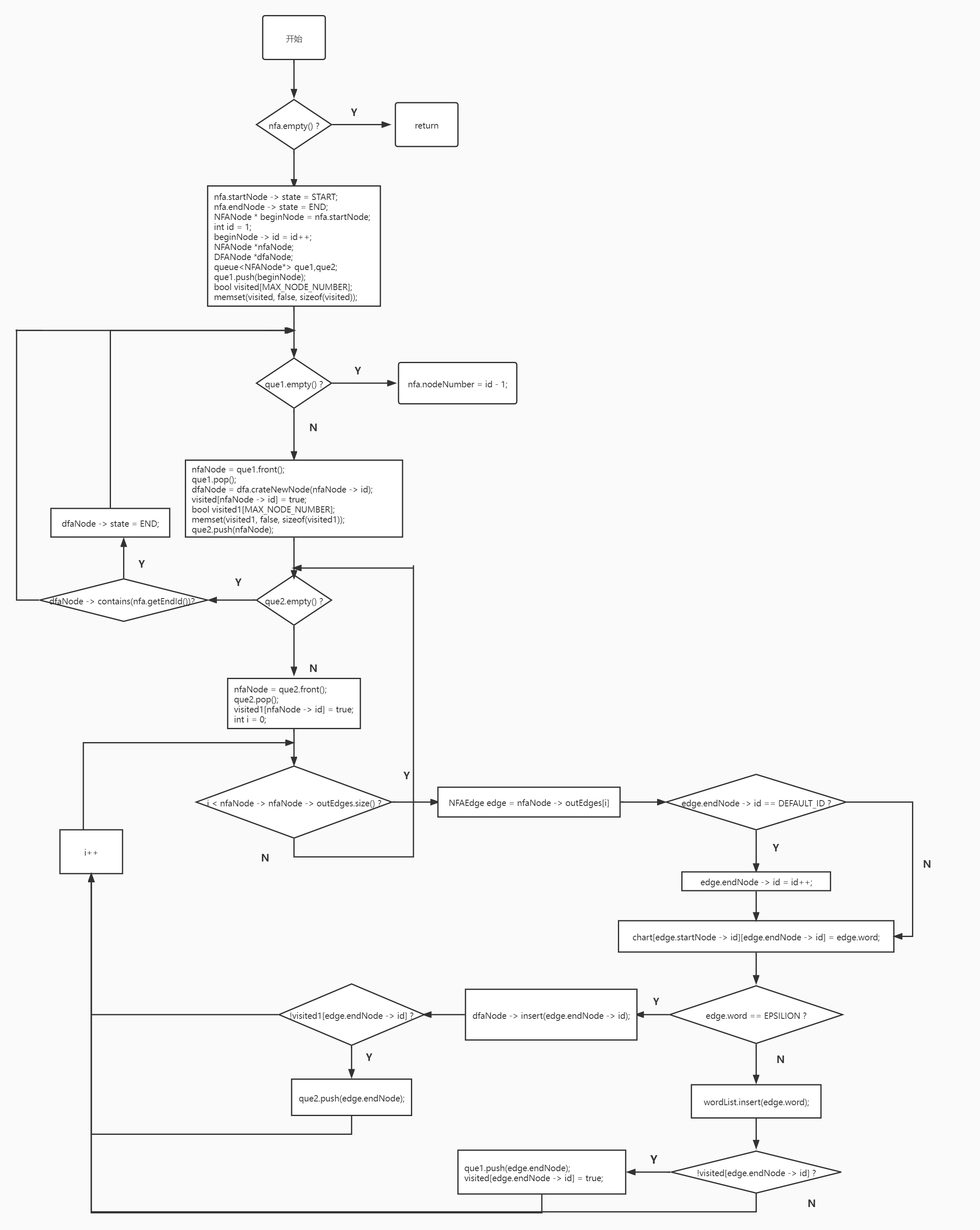
# 建立 DFA 的边
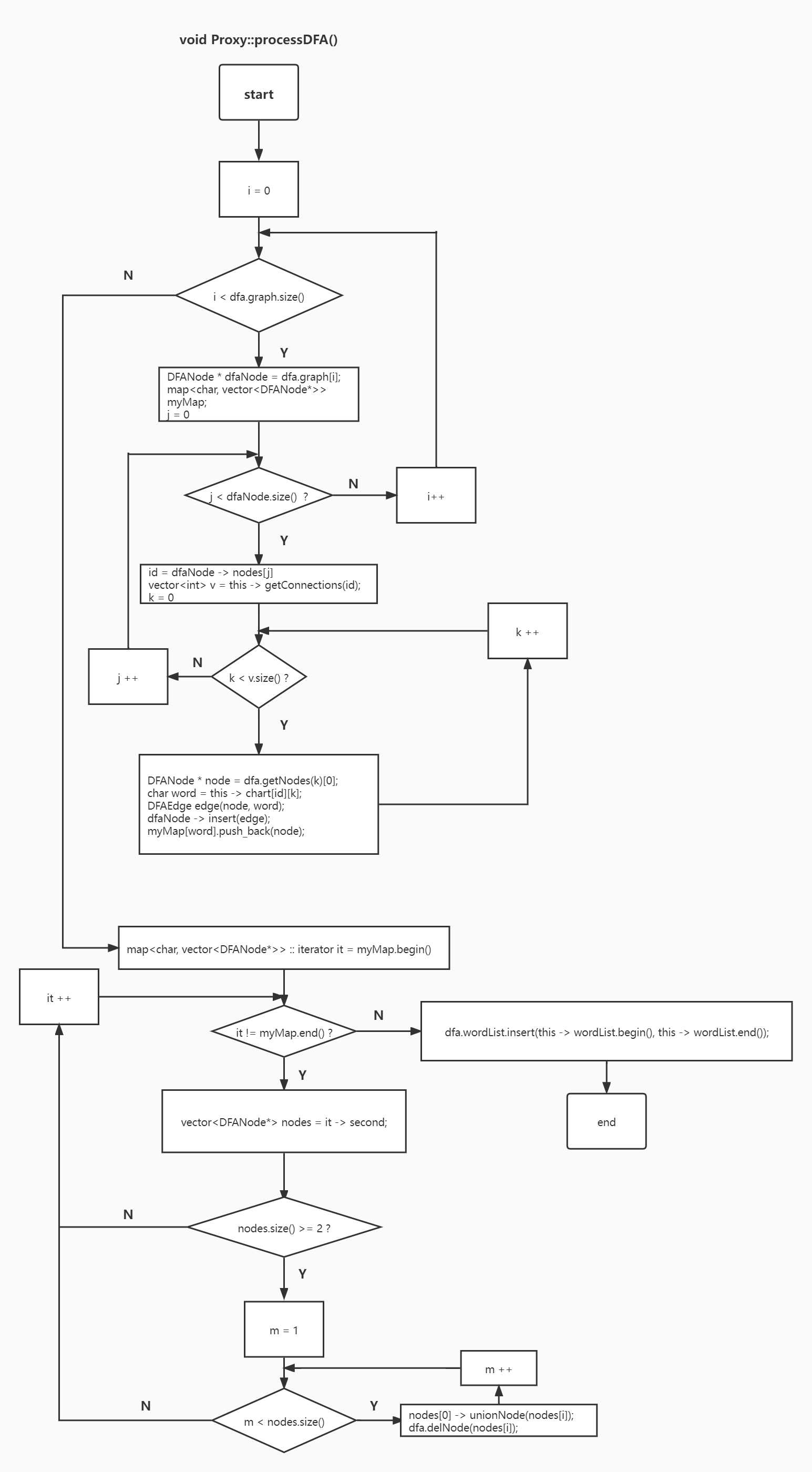
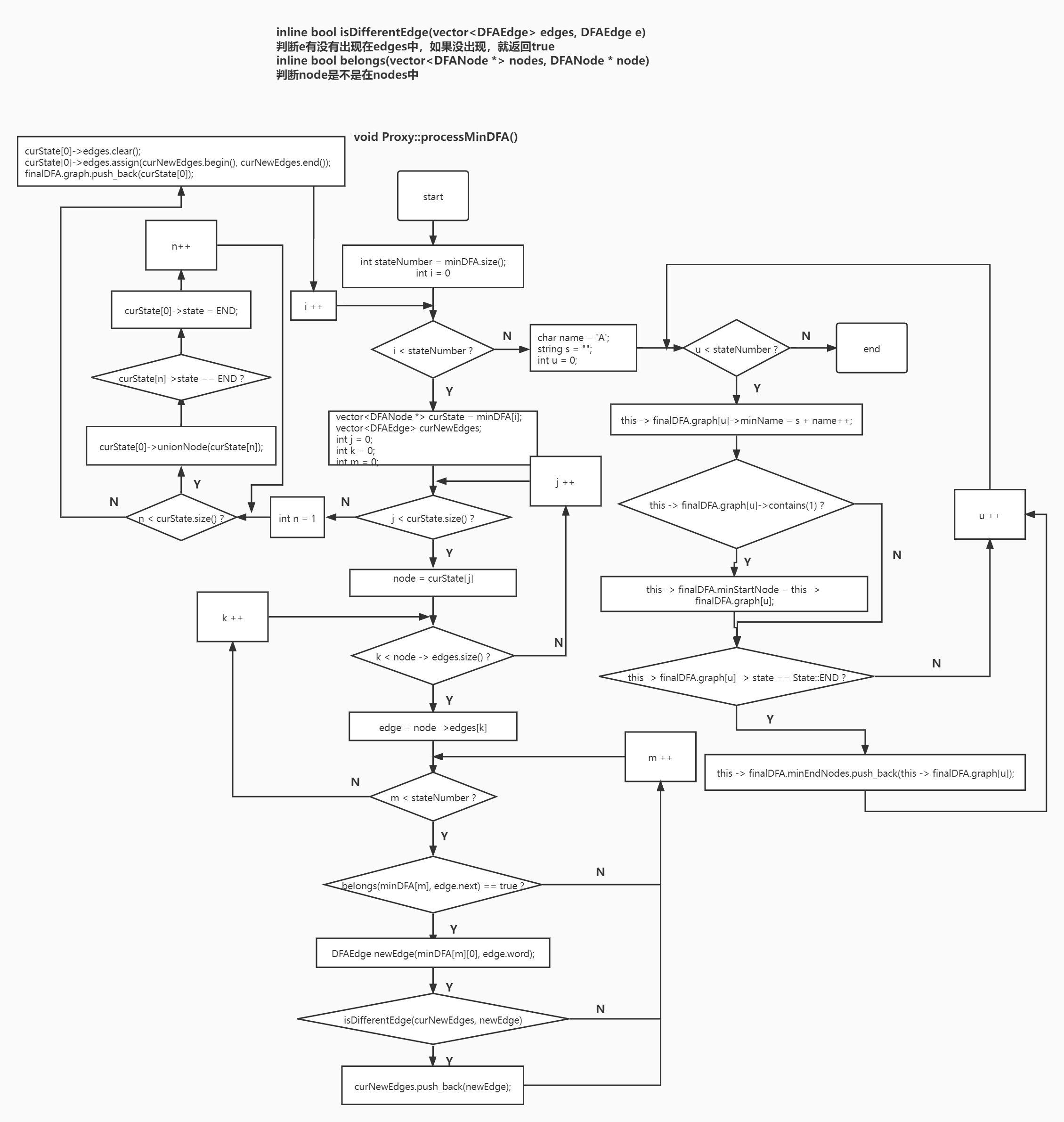
# 最小化 DFA
分为两个步骤:
- 求初态集合、终态集合并对这些集合进行划分,建立最后的 DFANode
- 建立 DFANode 之间的边,形成最小 DFA 图
# 集合划分,建立 DFANode
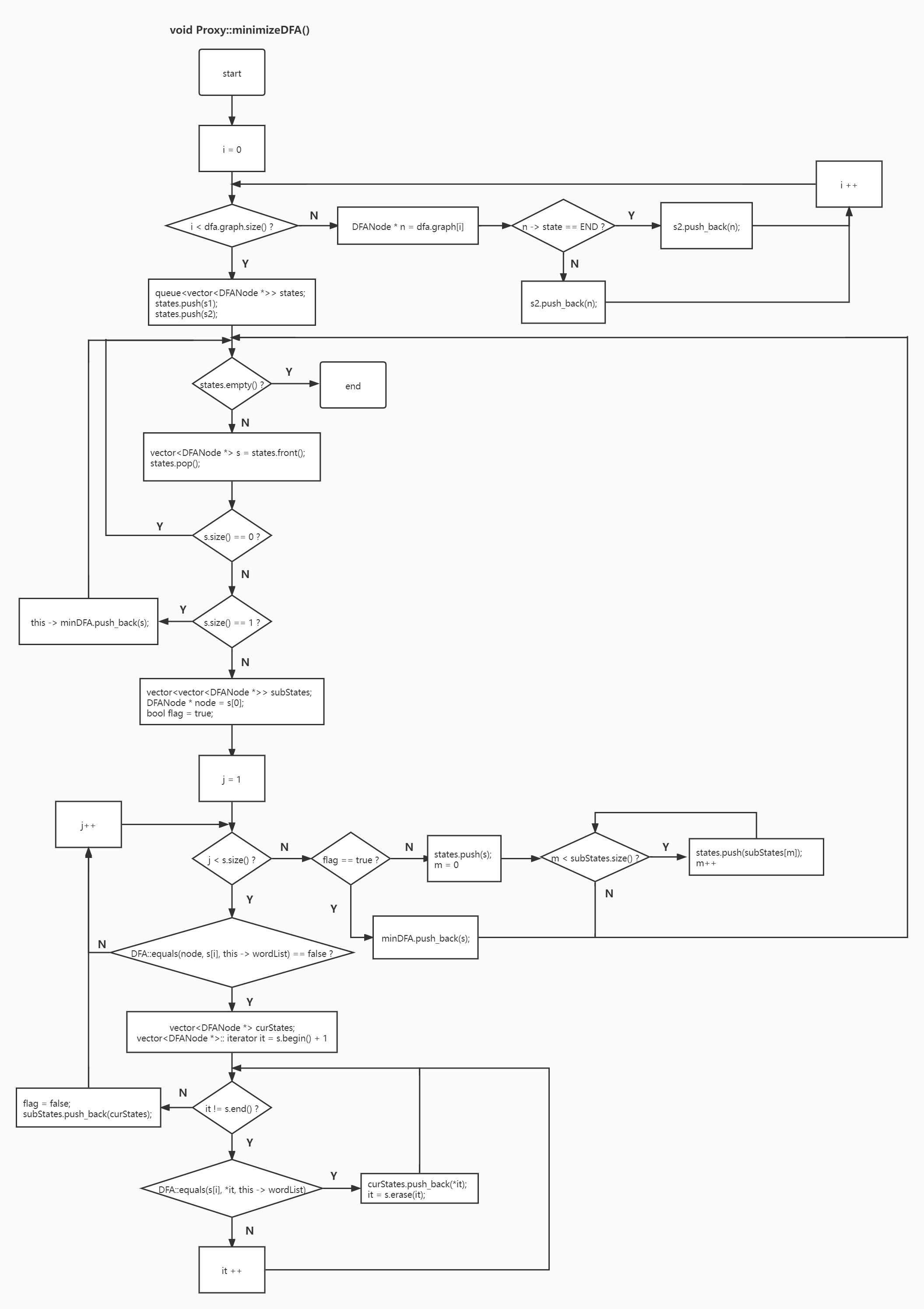
# 建立 DFANode 的边
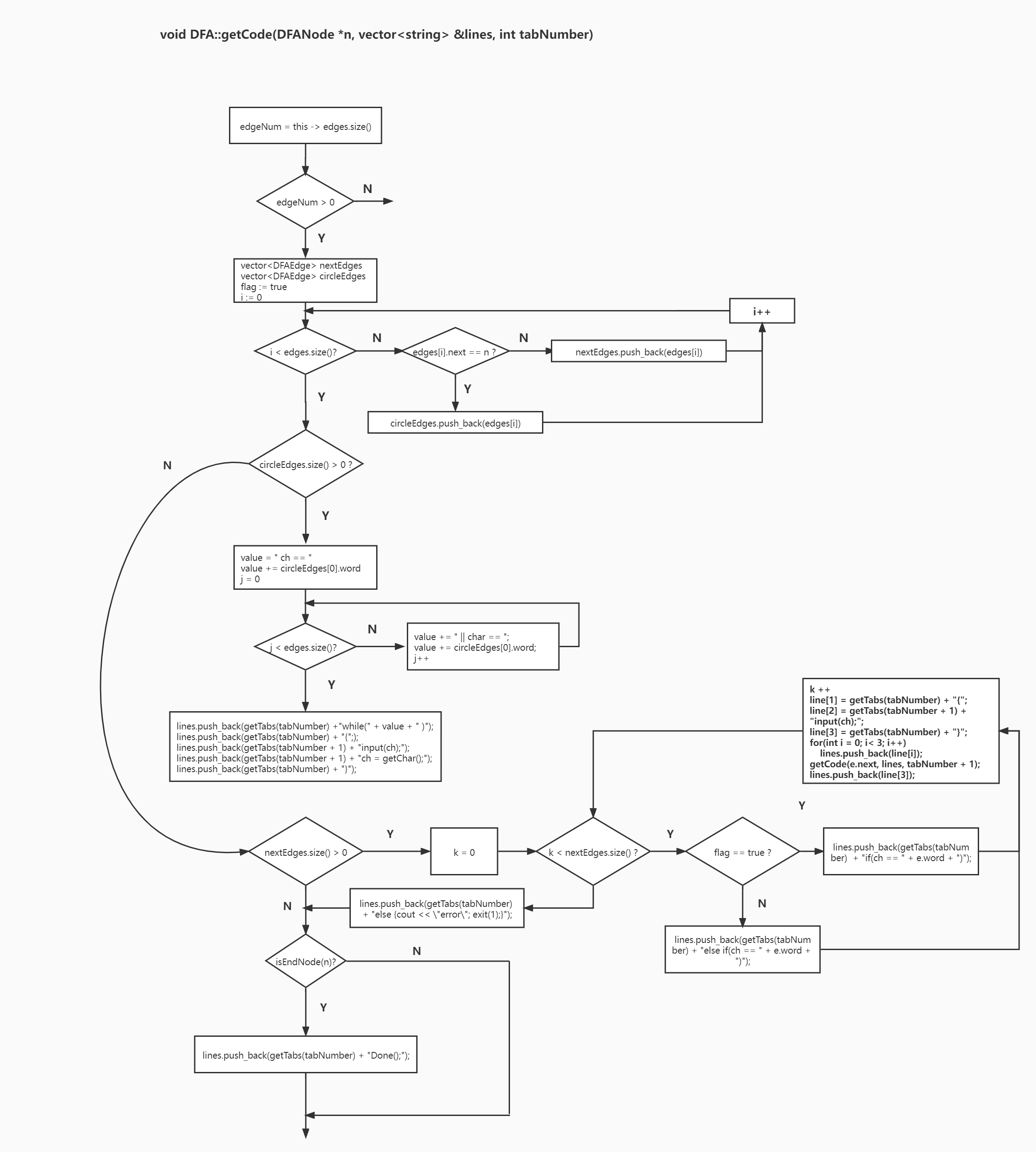
# 生成 c 语言代码
对于从个某结点出发的每一条边,分为两类,指向自己的,以及指向下一个结点的。对于指向自己的边,生成 while 语句;对于指向下一个结点的边,生成 if 语句,并且需要递归进入下一个结点,直到当前结点的状态为 END 时,结束递归,并回调。
# 枚举、结构体、类设计
# 枚举
定义了一个枚举 State,用于标记每个结点的状态,包括 START(开始节点), END(结束结点), NORMAL(其他结点)
|
enum State{
START,END,NORMAL
};
|
# 结构体
共四个结构体,NFANode,NFAEdge,DFANode,DFAEdge,分别代表一个 NFA 图的结点、一条 NFA 图的边、一个 DFA 图的结点、一个 DFA 图的边。接下来详细说明四个结构体的具体定义。
# NFANode
DFANode 用来描述一个 NFA 图的结点,其属性包括编号(id),状态 (state),入边 (inEdges),出边 (outEdges)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
struct NFANode{
int id;
State state;
vector<NFAEdge> inEdges;
vector<NFAEdge> outEdges;
NFANode(int i, State s) : id(i), state(s){}
NFANode(): id(DEFAULT_ID), state(NORMAL){}
};
|
# NFAEdge
NFAEdge 用于描述一条 NFA 图中的边,其属性包括开始结点 (startNode),结束结点 (endNode),处理的字符 (word)
|
struct NFAEdge{
NFANode * startNode;
NFANode * endNode;
char word;
NFAEdge(NFANode * s, NFANode * e, char c): startNode(s), endNode(e), word(c){}
NFAEdge(): startNode(NULL), endNode(NULL), word('\0'){}
};
|
# DFANode
DFANode 用于描述一个 DFA 图的结点,其属性包括该结点的 EPSILION 闭包 (nodes),由该结点出发的边 (edges),结点名 (minName),状态 (state),还有一系列的操作,如插入边,插入结点,输出结点信息等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
struct DFANode
{
set<int> nodes;
vector<DFAEdge> edges;
string minName;
State state = NORMAL;
bool contains(int id);
void insert(int id);
void insert(DFAEdge edge);
void unionNode(DFANode * node);
DFANode * process(char c);
string toString();
};
|
# DFAEdge
DFAEdge 用于描述一条 DFA 图的边,其属性包括指向的结点(next)和处理的字符(word)
|
struct DFAEdge
{
DFANode * next;
char word;
DFAEdge(DFANode *n, char c): next(n), word(c){}
};
|
一共定义了三个类,分别是 NFA, DFA, Proxy,其中 NFA 和 DFA 类分别代表一个 NFA 图和 DFA 图,Proxy 是代理类,用于代理有关 NFA 和 DFA 类的操作,具体包括生成 NFA 图、给 NFA 图编号并生成 DFA 图、最小化 DFA 图、生成 c 语言代码等操作。
# NFA
主要涉及到选择(a | b)闭包(a*),连接(ab)操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
class NFA{
public:
NFANode * startNode;
NFANode * endNode;
int nodeNumber;
NFA():startNode(NULL), endNode(NULL), nodeNumber(2){}
NFA(char c, int id1, int id2);
NFA(char c);
NFA(NFANode * s, NFANode * e): startNode(s), endNode(e){}
void operator=(const NFA &nfa);
void Or(const NFA &nfa);
void And(const NFA &nfa);
void Star();
bool isEmpty() const;
bool isEnd(int id) const;
int getEndId() const;
int getStartId() const;
};
|
# DFA
用于描述一个 DFA 图,其主要操作涉及到由该结点生成该结点对应的 c 语言代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
class DFA
{
public:
vector<DFANode*> graph;
vector<DFANode*> getNodes(int id);
DFANode *minStartNode;
vector<DFANode*> minEndNodes;
set<char> wordList;
DFANode* crateNewNode(int id);
static bool equals(DFANode *node1, DFANode *node2, set<char> words);
bool isEndNode(DFANode *node) const;
void delNode(DFANode *node);
void getCode(DFANode *n, vector<string> &lines, int tabNumber);
private:
string getTabs(int tabNumber);
};
|
# Proxy
代理 NFA 和 DFA 的操作,包括产生 NFA,产生 DFA,最小化 DFA
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| class Proxy
{
public:
string regularExpression;
NFA nfa;
DFA dfa;
vector<vector<DFANode *>> minDFA;
DFA finalDFA;
char chart[MAX_NODE_NUMBER][MAX_NODE_NUMBER];
string code;
set<char> wordList;
Proxy(const string regExp);
void serializeNFA();
void processDFA();
void minimizeDFA();
void processMinDFA();
void generateCode();
private:
NFA getNFA(const string regExp);
vector<int> getOrOperatorIndex(const string regExp);
bool isLetter(char ch);
int getRightBracketIndex(const string regExp, const int leftIndex);
vector<int> getConnections(int id);
};
|